

What Happens When You Ask AI to Extract Contract Metadata at Scale
A first benchmark on the gap between one-contract demos and contract-population workflows. Claude Opus 4.8, Sonnet 4.6, and GPT-5.5 tested on 100 SEC contracts.

The gap nobody demos
Ask a frontier model to pull the title, parties, and effective date from a single contract and it will probably get the answer right.
That is real progress.
It is also not the same problem as organizing a contract population.
So I ran a first benchmark: 100 real contracts, five metadata fields, three model runs, one fixed prompt, clean text-layer PDFs only.
The result was not a simple leaderboard. The more useful finding was where the workflow started to bend.
At one document, the experience feels almost magical. At 100 documents, the bottlenecks start to show: session limits, inconsistent handling of ambiguous fields, silent wrong answers, and model-specific trade-offs between accuracy, speed, and usage.
That matters because contract AI workflows are increasingly being built on top of specific model versions. And model access itself is now a planning variable. Last week’s export-control disruption affecting Anthropic’s Fable 5 and Mythos 5 models is an extreme example: access can change suddenly for reasons outside the workflow itself.
So this benchmark is partly about accuracy. But it is also about something more practical:
What happens when a capability that works in a demo has to survive a realistic contract-population workflow?
What I tested
Before you can do anything substantive with a contract population — M&A diligence, renewals management, migration into a CLM, risk analysis — you have to know what you are looking at.
Which documents are contracts at all?
What types of contracts?
What does the document call itself in its own language?
Who are the parties?
When did the agreement take effect?
Organizing contracts is not glamorous, but it is the dependency for everything downstream. Almost every contract intelligence workflow starts here, which is why this is the first benchmark I ran.
The scope was deliberately narrow: extract five metadata fields from each document and return one CSV row per document.
The five fields:
Document title — as stated in the heading or preamble
Party names — full legal names as stated in or around the preamble
Effective date — stated effective date, falling back to other best date available in the preamble
Preamble — verbatim introductory opening paragraph usually containing the party names and date
Recitals — verbatim background or procedural history
Nothing downstream. No clause extraction. No obligation tracking. No risk analysis. No product build.
That narrowness is the point. These are the fields many downstream workflows assume you already have, and they are mostly verifiable against the document itself. They also tend to appear near the beginning of the contract, which creates a more controlled extraction task than clause-level fields that may appear anywhere.
This benchmark is not trying to prove that AI can read contracts.
It is trying to test what happens when basic contract reading becomes part of a population-level workflow.
The documents
The sample consisted of 100 material contracts sourced from SEC EDGAR filings.
These are real, executed agreements, not synthetic examples. They are not a perfect analog for enterprise contract populations. They skew toward negotiated, higher-value agreements and generally arrive in cleaner condition than the contracts sitting in a shared drive, inbox archive, or legacy CLM export.
But they are useful for a first benchmark because they are:
real agreements,
publicly available at scale,
structurally similar to enterprise contracts,
and suitable for manual ground-truth annotation.
For this first run, I used clean text-layer PDFs only.
That means this is not yet a test of scanned contracts, bad OCR, image-only files, or corrupted text layers. Those conditions matter — a lot — but I wanted to isolate model choice first before adding document-quality variation.
The models and prompt
I tested three models against the same 100 documents using the same prompt semantics: Claude’s Sonnet 4.6 and Opus 4.8, and OpenAI’s GPT-5.5. I used Claude Cowork and OpenAI’s Codex to run these.
Model choice was the only variable in this run.
The prompt was fixed across all runs. It was approximately one page of context, written to strike a practical balance: specific enough to define the extraction task and output format, but not so optimized that it became a bespoke engineering exercise.
In other words, this was not a zero-shot “please extract metadata” prompt. But it was also not a heavily tuned production workflow.
It was the kind of first-version prompt a knowledgeable contracts professional could plausibly draft in an hour with a clear understanding of the desired output.
I’m not publishing the full prompt or workflow notes here because the point of this piece is the benchmark result, not a replication guide. But the methodology matters, so I’ve described the corpus, fields, scoring approach, and limitations clearly enough for the findings to be contextualized and evaluated.
How I scored the results
I scored the outputs across three dimensions.
First: field return rate. Did the model return a value for the field at all? I tracked this separately from accuracy because a blank output and a wrong output create different risks. In this run, it was less of a differentiator between models.
Second: accuracy. For free text fields — title, parties, preamble, recitals — I assessed substantive match against the manually annotated ground truth. For effective date – I used exact match after date conversion to YYYY-MM-DD.
Third: time and usage. I tracked wall-clock runtime and session usage consumed per model, per run.
A note on ground truth: contract metadata is often less objective than it looks.
Take document title. Sometimes the cover page says one thing and the opening paragraph says another. Sometimes the heading includes “Executed Version,” “Confidential,” “Exhibit 10.3,” or party names that are not really part of the title. Sometimes the preamble characterizes the document differently from the header.
Effective dates are similar. Across this sample, effective dates appeared in several forms: stated explicitly in the preamble, defined by reference elsewhere in the document, implied by an “as of” convention, or left to the signature block.
So the benchmark uses documented annotation rules applied consistently. Ambiguous cases are flagged rather than forced.
The goal is not a perfect golden set. For contract populations, the term “golden set” often oversells the certainty available. The goal is a reasonably standardized reference set — and the difficulty of building even that is part of the finding.
The headline result
The headline result is not simply that one model performed better than another.
The more useful findings are that 1-the errors were patterned and 2-there are trade-offs between speed, usage and accuracy.
The models did not fail randomly. They struggled on the same kinds of contract complexity:
ambiguous titles,
party-name exactness,
effective dates defined by reference,
and multi-party agreements.
That matters because it changes how to interpret the benchmark.
If errors were random, the answer would be “use the most accurate model.” But if errors cluster around specific document structures, then knowing your contract population becomes key prior to, or in parallel with model selection.
A better model helps. But a better understanding of the document population may help more.
Speed and usage
In addition, the three models diverged sharply on both accuracy as well as speed and session usage.
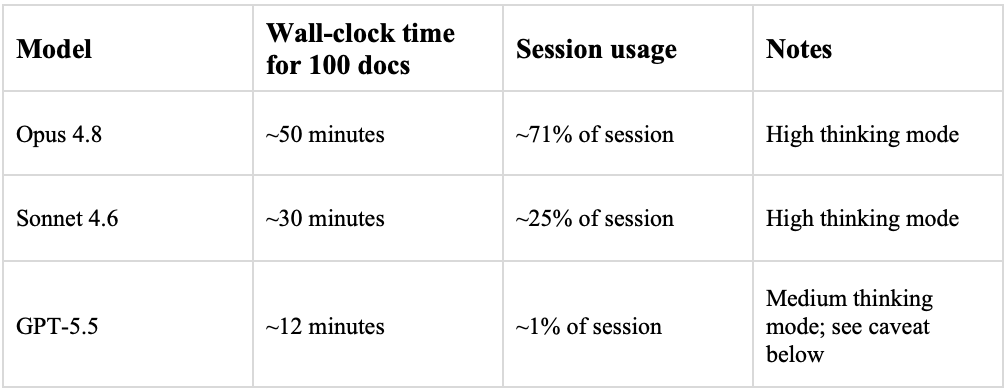
A few caveats.
These runs were performed using paid consumer tiers (Anthropic Pro, ChatGPT Plus), not enterprise licenses. That matters because most company use cases would likely require enterprise controls for data security, confidentiality, admin oversight, and related needs. Usage limits and economics may differ materially in those environments.
The GPT-5.5 usage figure also deserves a specific note. Current GPT-5.5 pricing appears unusually favorable and may be subsidized as part of a competitive user-acquisition strategy. That does not mean the figure is meaningless, but it should not be treated as a durable long-term cost benchmark. API usage at scale may tell a different story.
Still, the operational difference was real.
A single Claude Opus 4.8 run on 100 documents consumed roughly 71% of a paid consumer-tier session. That is manageable for one experiment. It is far less likely to be a comfortable foundation for routine extraction work at scale.
At 1,000 documents, consumer-tier session limits would likely become a workflow design constraint well before the task itself is complete.
Accuracy by field
Claude Opus 4.8 performed best in terms of accuracy both overall and for each specific field. GPT-5.5 and Claude Sonnet 4.6 performed similarly overall but varied significantly in terms of field-level performance.
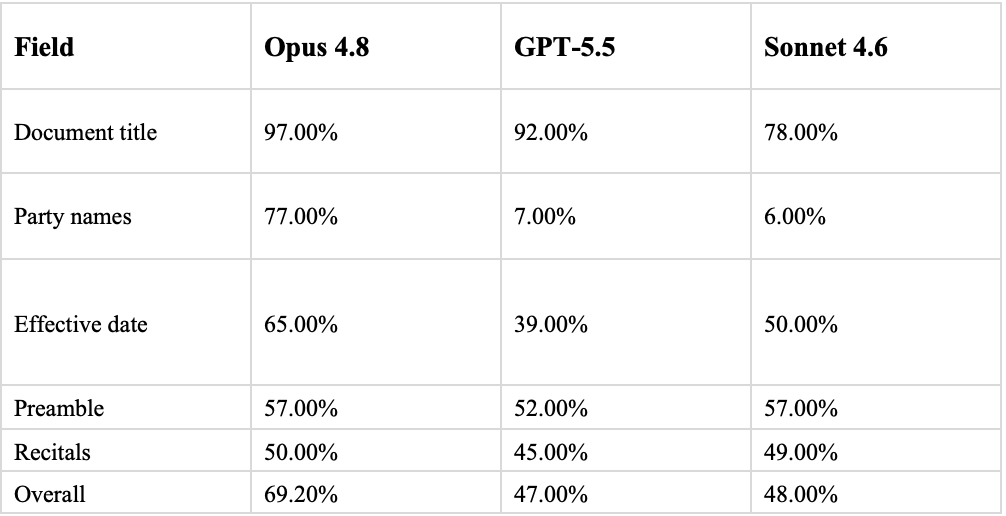
n = 100 documents. Effective date scored on normalized exact match; free-text fields scored on substantive match.
The accuracy gap between models was real, but the spread was not the whole story. The more important question is where each model was wrong, and whether those errors would matter for the workflow.
For example, if one model is five percentage points more accurate but consumes nearly three times the session capacity, that may or may not be worth it. The answer depends on the use case, QC tolerance, document volume, and whether the incremental errors are concentrated in fields that actually matter.
That is why this benchmark is less useful as a leaderboard than as a workflow diagnostic.
As another example, for party names: more lenient criteria (including partial matches – such as where the model found one but not all of the parties) yielded the following results, with substantial improvements for both GPT-5.5 and Sonnet 4.6:
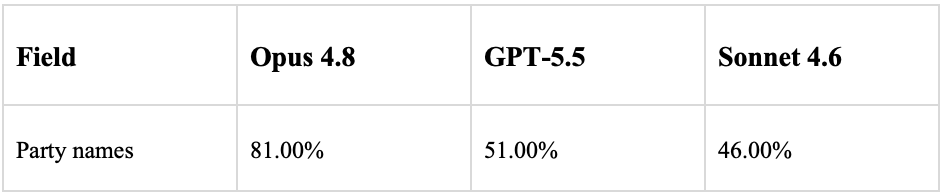
Where the models failed
The failure modes were not random.
Here are some common ones:
1. Document title ambiguity
Title was more ambiguous than it initially appears.
Some documents had a clean title in the heading. Others had a heading that included filing labels, stamps, party names, or version indicators. In some cases, the heading and preamble characterized the document differently.
For example: “FOURTH AMENDMENT TO COMMON SECURITY AND ACCOUNT AGREEMENT” (doc header) vs. “Fourth Amendment” (preamble).
This produced two kinds of issues.
First, models sometimes selected different title sources: header versus preamble. Second, even within the same model run, title-selection behavior was not always consistent.
That inconsistency matters more than a one-off wrong answer. A single bad title can be corrected. An inconsistent title-selection rule creates downstream cleanup work.
2. Party-name exactness
There were some significant party name mistakes that included missing relevant entity names, particularly in multi-party agreements.
However, more often models returned party names that were substantively correct but not exact.
Examples include:
Including extraneous text in addition to a relevant party name,
omitting legal suffixes,
omitting punctuation
In normal reading, these second class of errors are not serious mistakes. A person understands the answer.
But in a structured data workflow, small variations matter. Party names often become merge keys, deduplication inputs, entity-resolution candidates, or search filters. “Close enough” may be fine for a summary but problematic for a migration or analytics workflow.
This is one of the recurring lessons of contract data work: an answer can be substantively right and still operationally messy.
3. Effective-date variation
Effective dates were one of the hardest structured fields.
The reason is not that models cannot read dates. The reason is that contracts state effective dates in various ways.
Some are explicit:
“This Agreement is effective as of January 1, 2024.”
Others are indirect:
“This Agreement is entered into as of the date first written above.”
Others define the date elsewhere, refer to a closing, rely on signature timing, or contain several dates that look plausible but serve different functions.
When models relied too heavily on a standard preamble pattern, they missed dates defined elsewhere. When models searched more broadly, they sometimes surfaced the wrong date: a prior agreement date, notice date, recital date, or signature date.
This is exactly the kind of field where a model can look confident while being wrong.
What did not fail
It is worth saying what worked.
On clean text-layer PDFs with standard preamble structure, all three models were generally consistent. They identified ordinary titles, ordinary party names, and explicitly stated effective dates reasonably well.
That is important. This is not an argument that model-based extraction does not work.
It does work.
The question is where it stops working cleanly, how visibly it fails, and how much workflow you need around it before the output can be trusted.
The failures above are patterned, which means they are addressable. Better prompts can help. Post-processing rules can help. Entity normalization can help. QC sampling can help. A human-in-the-loop review step can help.
But none of that is free.
The model is only one part of the workflow.
The silent failure problem
The most important operational finding was not that the models made mistakes.
It was that the wrong answers looked exactly like the right answers.
Across all three models, every field in every document received a value. No uncertainty flags. No “I could not determine this.” No visible indication in the CSV that a given value required review.
That is convenient until it is dangerous.
At 100 documents, a human QC pass can catch many of these issues.
At 1,000 documents, that is no longer true unless sampling is built into the workflow explicitly. At 10,000 documents, even a small systematic error becomes a data-quality problem. At 100,000 documents, a 2% intervention rate means 2,000 human interventions.
The operational risk is not merely that the model gets something wrong.
It is that the model gets something wrong confidently, and confidence is the only signal available downstream.
What this means
The first lesson: model choice mattered, but document structure mattered more.
Across all three models, the lowest-accuracy documents were not random. They were the documents missing preambles, where effective dates were not clearly defined, where there were more than two named parties, or title/preamble mismatches.
That means knowing your contract population is key prior to model selection. If your population has a high concentration of those structures, prompt design, field definitions, and QC process may matter more than switching models.
The second lesson: speed and usage tell a different story than accuracy.
Claude Opus 4.8 was directionally strongest on accuracy, but it was also the slowest and consumed the most session capacity. Claude Sonnet 4.6 was materially faster and used less session capacity. GPT-5.5 was fastest and cheapest by apparent session usage, but with pricing and durability caveats.
That creates a practical trade-off.
If Claude Opus 4.8’s overall accuracy advantage is 22 percentage points, the decision is not simply “use Claude Opus 4.8.” The decision is whether those extra correct answers are worth the added time, usage constraint, and workflow friction for the specific task.
The third lesson: consumer-tier tools can benchmark the workflow, but they are not the workflow at scale.
At 100 documents, they are usable. At 1,000, session limits and manual handling become serious constraints. At higher volumes, API access, retry logic, QC sampling, structured storage, and review workflows become the relevant comparison.
The fourth lesson: silent failures require explicit QC.
Do not treat a complete CSV as a correct CSV.
A model returning values for every field is not the same thing as a validated extraction workflow. If the output will be used for diligence, migration, analytics, obligation tracking, or system-of-record updates, some QC process has to be designed into the workflow.
Takeaways
These thresholds are directional, based on this first run. I will refine them as the benchmark develops.
10 documents or fewer
Use the chat interface.
At this volume, setup overhead matters more than workflow sophistication. Drag-and-drop, ask for the fields, copy the output into a spreadsheet, and manually check the results.
Model choice is probably less important than clear instructions and human review.
Around 100 documents
The chat interface still works, but the constraints become visible.
You need a repeatable prompt, a consistent output schema, a place to store the results, and a QC pass before using the output downstream. Watch especially for ambiguous titles, effective dates, and multi-party agreements.
This is the tier where many ad hoc legal ops and in-house requests live. It is also where teams can fool themselves into thinking they have a process when they really have a clever manual workaround.
100 to 1,000+ documents
The workflow around the model starts to matter more than the model.
You need consistent prompting, structured output, QC sampling, failure logging, and a storage layer that is not a manually assembled spreadsheet. Consumer-tier session limits become impractical. API access becomes the relevant comparison.
The per-document model cost may be low. The human time cost of managing an ad hoc process at this scale is likely much higher.
10,000+ documents
The question changes.
This is no longer “which model should I use?” It becomes “what operating model do we need?”
Build, buy, outsource, or run a formal internal data operation — but do not mistake model access for workflow readiness. At this scale, reliability, review design, exception handling, and data governance become the work.
The useful distinction
The demo version of contract extraction asks:
Can the model read this contract?
The operational version asks:
Can the workflow produce structured data across this population, with known accuracy, acceptable review burden, manageable failure modes, and outputs that downstream users can trust?
Those are different questions.
The first is increasingly easy to answer.
The second is where most of the real work still lives.
What comes next
This is a first data point, not a conclusion.
I will publish additional cuts as the benchmark produces useful findings: document-quality conditions, additional models, larger scale tiers, and the operational differences between chat-based and API-based workflows.
If you found this useful, the best signal you can send is forwarding it to someone who is about to make a decision about contract extraction tooling based on a demo.